Testing BBC iPlayer: Krispy Gherkin feature file aggregator

Miguel Gonzalez
Senior Web Developer
Tagged with:
N,B. All the code snippets mentioned below can be found in github
Hi, I'm a senior web developer at BBC iPlayer. I was part of the team that delivered a truly responsive BBC iPlayer, launched last March. The team take pride in collectively taking responsibility for implementing meaningful, working, and useful tests that can get us closer to continuous delivery.
One of the problems we have been facing at BBC iPlayer for a long time is the way we approach documenting the features included in the project and our test strategy. There is no silver bullet here, as it's hard to find a solution that is fast, accurate, stable, and that works for developers, developers-in-test and product owners.
Our Unit tests:
As developers, we usually find it easy, or at least more natural, to test code comprising mostly logic. This usually is unit testing models, or data-handling code. On the other hand, testing the markup generation, the view in the MVC, can be tricky because of all the difficulties to run tests over HTML code and the usual need to have a browser-like element to interpret it, such as WebDriver or Selenium.
In recent months we have started migrating all of our views away from the BBC templating engine Spectrum. The engine of choice was Mustache, since it’s almost logic-less, which enforces moving the logic into proper code, leaving clean templates that are easily reused for the front-end or backend counterpart.
We call “Presenters” the classes that wrap the logic providing data to the mustache views. These should:
Be as independent from the rest of the codebase as possible, having all the dependencies injected.
Contain a single public method called “present”, which will generate the HTML markup.
This isolation of Presenters + Mustache templates has allowed us to unit test view components very easily with PHPUnit and Symphony’s Crawley (a markup parser).
While that covers the PHP we have Javascript unit testing with Jasmine which we find works well for us.
Behaviour and Feature Tests:
The Behaviour tests are another matter, half of them are Javascript unit tests implemented as Jasmine tests. These are reliable and are part of the build process.
The other half are described by means of Gherkin feature files, which we use the Ruby library Cucumber to implement. Most of these tests use the Selenium Web Driver to spin up a real instance of Firefox or a PhantomJS instance and check behaviours and assertions. These tests have proven hard to write and to maintain. Another important blocker for us is that in this setup we have 60+ feature files (each holding any number of tests) that take around 3 hours to run in total and, most importantly, it needs the website to be tested to be running in some server. This causes the tests to be rarely run together and due to this they are not maintained easily and have become unreliable.
We tried to fix this by introducing priority tags (p1, p2, p3) which would mirror the importance of features which must be passing before we deploy live. The aim was to have a suite that could run as a downstream job right after having deployed the site in a test environment.
However as time drew on, the number of p1's (highest priority) increased as did the time they took to run. We found ourselves back where we started: reliability decreased as fixes were slower to be implemented. Eventually we began to lose faith in them and deploying regardless of their status. Failing unit tests would never allow us to deploy the website, which is what we wanted to aim for.
It seemed like we needed a solution which could have the product-facing benefits of the feature files and the speed and reliability of our combo Presenters+Mustache view tests.
The Problem with Feature Tests:
As we moved away from Spectrum, we started porting more and more features from the feature files as unit tests. We needed to be able to remove some of the duplicated Cucumber tests which were run already by PHPunit, but doing this would decrease their visibility as members of the department rely on reading these feature files to confirm how a particular feature should act on the site. Besides, having the description of what a Unit test is testing in a completely different part of the code base increases how disconnected test and development felt.
Solving the First Feature Test Problem:
The first step was creating a script which could use reflection to read the annotations of each PHPunit test, and if information about a feature file was found, containing the scenario description, add it to an autogenerated feature file.
As an example, when we started this process, the original feature would’ve been found in a tv_homepage.feature file, tagged as @unit:

Which would have been picked up by the script and been added to a “tv_homepage_phpunit.feature” file. This script is run as part of the build process, so all the features are found in the same directory in the workspace.
The “testable feature” problem
Cucumber is really good at allowing the tester to include a group of examples that will be actually tested when the test runs. It does so by means of an “example table”. Our approach was lacking that feature, so we built a way to get these examples from the PHP code that implements a test, so the actual examples in the auto-generated feature file are being tested.
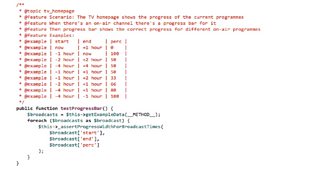
This is implemented by using reflection, and it’s proven to be something that all the developers in the team like to use, since it’s a very clear and easy way to describe and modify the examples that we want tested.
The visibility problem
As described, all the feature files end up being in the same directory, which is very convenient, but it’s not easy to browse, or share. The lack of visibility of these feature files is, in our opinion, the most important problem to fix. Some people in the team have been trying a SAAS product called Relish, which parses the feature files. Besides its price, a problem is that it needs to interact with our Git repositories, which don’t have the autogenerated features files from the annotations. It’s also convoluted to manage the permissions, and to tie it to our workflow. This solution was less than ideal.
Our proposal was to build a parser that would convert all the feature files (manually written and autogenerated) into a browsable format. We decided to use PHP Behat’s Gherkin parser and generate a JSON structure representing all our scenarios, topics, and tags.
The last step was to build a simple interface using AngularJS that would show all the scenarios in a user-friendly way, allowing easy search and filtering. We call it Kripsy Gherkin, since it’s a tasty way to explore the Gherkin files.
The biggest advantage of this is that, the interface comprising nothing but static files, can be happily served from Hudon’s or Jenkins’ workspace, or even downloaded and opened in your browser from your file system, no server required. This solves the permissions issue, since you need a BBC cert to get access to it.
Current status and future work
More and more features are being ported to unit tests, which run fast and as part of the build process. Both the traditional feature files and the newly autogenerated ones have had their visibility increased. The next step is to find a way to do the same for all the Javascript tests that are implemented in Jasmine.
Now that we had a mechanism to view all our features (Cucumber and PHP, JS coming soon), we want to migrate as many tests as possible from Cucumber to PHP so they could be run as part of the build (as PHP tests) and decrease Cucumber’s run time.
We are also introducing Zend's Controller test suite and using fixtured data to help move more of the Cucumber features into PHP Controller tests. This also improves our PHP coverage reports which is a double win.
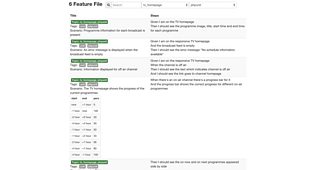
You can see below a screenshot of the software showing the unit tests described in this article.
Miguel Gonzalez is Senior Web Developer, BBC iPlayer
Thanks to Craig Taub for his help in preparing this post
