A machine learning readiness index

Philip Robinson
Lead Architect, Technology, Strategy & Architecture
There has been a surge in machine learning capabilities over the last 3–5 years, driven by fundamental improvements in algorithms, advances in computer hardware, increasing volumes of data, increased knowledge-bases, communities and tools for learning, and developing and incorporating machine learning capabilities in products. In as much as machine learning has advanced, such that we have a better view of possibilities, nervousness and discussion around ethics, liability and social good have escalated. Alongside the many recent breakthroughs in machine learning, mishaps and fatal accidents involving machines, such as the recent Autonomous Vehicle incident in Arizona, engender a sense of caution when deploying machine learning, especially in human-critical environments. Understanding the causes of such incidents reinforces the reality of machine learning amidst the hype: machine learning is large-scale calculations, comparisons and selections of the best statistical possibility, limited by the extensiveness of data about the past and its ability to correctly and comprehensively encode a perception of the present.
Many of the incidents and accidents in machine learning have been associated with a current hard problem known as “Adversarial Examples”. These occur when slight changes in the physical environment, which would be routinely discounted by humans, severely compromise the reliability of a machine learning system’s decision making. For example, a strip of white tape placed over a stop sign could change the machine learning system’s calculations and ability to distinguish one road sign from another. Accidental or intentional alterations in everyday scenes, sounds and objects such as graffiti or inevitable wear-and-tear ‘confuse’ machine learning algorithms, leading to unreliable reasoning. Such adversarial examples could explain why incidents such as the Arizona accident occur. Yet it is by realising the susceptibility of machine learning to seemingly trivial, everyday adjustments that its true capabilities and limitations are better understood.
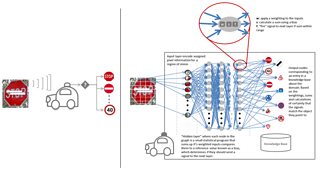
Clearly a fatal accident in an autonomous vehicle is far more critical and alarming than the failure of a recommendation system to present relevant programmes on someone’s media homepage. However we should bear in mind that similar concepts and technologies are at work behind the scenes. Consider a journalist relying on face and object recognition for documenting and validating facts in a story that could affect the reputations of people and places. Dependence on machine learning could lead to inaccuracies being introduced to stories and compromising the trustworthiness of journalism if these types of errors were to frequently occur without scrutiny and correction. In some cases the work of review and correction is more tedious than just doing the task at the onset.
Machine learning capabilities such as computer vision, audio processing and natural language understanding, already used in product-ready media workflows, are all susceptible to the types of adversarial examples mentioned above. In addition, machine learning algorithms still consume large amounts of computational and storage capacity and are difficult to optimize without sacrificing quality and rigour. There are some applications where machine learning is ‘production-ready’ and others where either computational capacity or algorithmic capabilities are inadequate. A means of articulating ‘readiness’ in a meaningful, indicative manner would be helpful in navigating the landscape of machine learning capabilities.
In BBC Technology Strategy & Architecture (TS&A) we have been working with our technology partners to better understand the scope, limitations and roadmaps of their machine learning products and services and inform the following discussions:
- Where should we invest in research?
- In what types of strategic partnerships do we need to engage?
- Where should we be thinking about trials and pilots?
- What should be part of our next adoption plan?
- What is still too early to be on our radar?
Most of our discussion and analysis was around automation and the possibility of supplementing or entirely replacing human cognitive function in traditionally manual, media workflow tasks. Cognitive function includes perception, decision making and execution tasks, each bringing different challenges for automation. These discussions gave rise to what we refer to as “The Machine Learning Readiness Index” shown in the figure below.
It is a 0–7 rating scheme, where each increasing level designates a higher level of capability readiness for a specified application. ‘Machine Learning Readiness’ is defined as the ability of a Machine Learning capability to replace human cognitive function in a given scenario. Machine Learning Readiness refers more specifically to the fitness or suitability of an approach using one or more machine learning capabilities to solve a selected problem in a production workflow, which would normally rely on human cognition.
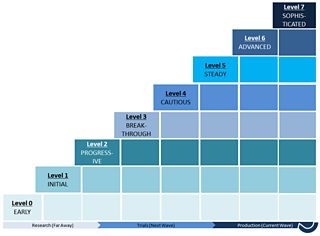
The levels in the index are described in following:
Level 0 (EARLY): capabilities at this stage are conceptual in nature. There are suggestions and ideas about how the capability might work and some theoretical or even simulated workflows presented, but no practical, peer-reviewed proof or demonstration published. Applications and benefits are propositional and user experience shown through prototypes and mockups.
Level 1 (INITIAL): capabilities at this stage are developed with a working model, proving that a concept is at least realizable. However, in order to demonstrate benefits at scale, there are still required developments of dependent capabilities (not necessarily machine learning, but in other domains e.g. animation, visualization and data processing), computational capacity (processing, storage and networking) and training data in order to assess in a real workflow. Capabilities may remain at this stage for a long period of time if there is little market demand or the required computational capacities and training data are far beyond what is available in current practice.
Level 2 (PROGRESSIVE): capabilities at this stage have proof that they could work in practice. The fundamental computational and algorithmic challenges have been solved but there is still insufficient training data to enable wider application to real-world scenarios and to tune the model and learning algorithm. The next challenge is then collecting relevant training data and identifying strategies for optimising its performance.
Level 3 (BREAKTHROUGH): at this stage there is an improved understanding of a capability’s limitations (the minimum conditions under which it provides useful results) and tuning parameters (adjustable properties of data, algorithms and computation that controllably affect the behavior, performance and quality of the capability). The capability may be released to the public as “beta”, where the aim is to enhance the training set and do early experiments with usage at scale.
Level 4 (CAUTIOUS): at this stage the capability’s performance is stable but the outputs are not always reliable. The capability may be susceptible to nuanced, cultural or other domain-specific peculiarities (e.g. jargon, dialects, gestures, icons, colour associations) that deviate from its training. For this reason the capability is not trusted to function without human supervision and correction. It may provide the “first-cut” product but the workflow will include a mandatory quality control process.
Level 5 (STEADY): at this stage, there are certain scenarios that under known, controllable conditions and properties of inputs, the capability provides predictable, correct results. It can hence be entrusted in a production workflow for selected domains with redirects, escalations or exception handling that notifies and engages a human should the domain’s boundary conditions be exceeded. The machine capability is said to perform as good as a human in its restricted domain, at a cheaper cost and more reliably over an extended period of time (i.e. humans get tired and make mistakes). Human supervision is monitoring notifications and alerts, such that quality control and intervention are on an on-demand basis. Consider automated chat-bots used in call-centres that redirect conversations to supervisors if, say, a complaint’s tone or matter becomes overly sensitive.
Level 6 (ADVANCED): capabilities at this stage are deemed to work better than humans, cheaper, equivalent to better quality outputs and more reliably over extended periods of time in selected domains. Supervision is minimal and focused on ensuring the overall workflow and system remains available, rather than the quality of the capability. Logs may be reviewed in retrospect in order to continuously improve the capability, but improvements at this stage are marginal. The machine capability would be favoured over a human for high-risk situations that could affect the life or livelihood of the individual performing the function. However, a human may still be selected or given supervisory, overriding control if there are concerns of a wider population being affected by incidents of failure.
Level 7 (SOPHISTICATED): capabilities at this stage are fully autonomous and are considered capable of achieving levels of quality, performance and reliability beyond human capability in most domains. These capabilities would be favoured over humans in highly-critical or high-risk tasks that could affect the reputation of an organization or the livelihood and well-being of a population beyond the individual performing the function.
The Machine Learning Readiness Index can then be further used as a visual map providing orientation (where we currently are), destination options (where we would like to go), optional pathways (what is possible) and direction (what needs to be done to get there). When applying the Machine Learning Readiness Index there are three questions and hence types of information to be gathered:
- Current readiness: what level of readiness is currently possible?
- Desired readiness: what level of readiness would we like to be possible in a given time horizon, based on audience and business indicators
- Projected readiness: what level of readiness appears likely to be possible in a given time horizon, based on technology assessment and market indicators?
Answering these questions strengthens a strategic position to communicate and challenge our interests, disinterests, intentions and priorities to partners, providers and the public. A further objective is using the framework as the background to support higher level discussion around machine learning reality, fact and fiction with a non-technical audience. Much of the apprehension around machine learning adoption is irrational and based on sensationalism, but recent incidents, as mentioned earlier, do give reason for concern.
An example outcome is shown below based on a set of hypothetical use-cases (this figure is for illustration purposes only and does not represent our current position regarding the scenarios presented).
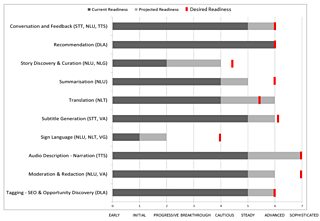
Such a map can be applied at a use-case, product, platform, organisation or industrial partnership and consortia level, assisting in conversations around strategy. For example, here are some messages that could be taken from the above map:
Conversation and Feedback scenarios using Speech-to-Text (STT), Natural Language Understanding (NLU) and Text-to-Speech (TTS) have a current readiness of level 5 – steady but a projected readiness of level 6, equal to the desired level of readiness. This suggests a need for partnerships to develop trials and pilots over the next time horizon in order to achieve a transition to the advanced stage of readiness.
Recommendation scenarios using Deep Learning and Analytics (DLA) have a current readiness of level 6 – Advanced, equivalent to the desired readiness, and there are no further advances projected. This suggests commodity and decisions should be focused on selecting the right vendor.
The question of machine learning readiness is often focused on the organisation as opposed to the technology capability. This framework is not an assessment of an organisation’s fitness for incorporating machine learning capabilities but rather of the capabilities’ readiness for bringing value to the organisation. The readiness index is not an absolute science and is dependent on collective, subjective opinion, based on a shared understanding of scenarios and machine learning capabilities. In particular the forecasting done with the framework is nothing more than imprecise impressions and best guesses. The intent is not to forego rigorous benchmarking and comparison of solutions using real data and workloads, but it serves the purpose of giving a high-level picture of market relevance at a point in time.
An alternative approach to creating such a view is to build an automated testing pipeline for each capability type with test data from across scenarios, reporting on selected test metrics. Although this appears to be more quantitative and metrics-driven, there is still a need to interpret the numbers and make a judgement about the fitness of the evaluated capabilities for the scenarios under test. Machine learning capabilities continue to evolve with advances in algorithms, frameworks and compute capacity. As a media organisation we need to keep our eyes on these developments in order to make informed judgements about meaningful, realistic ways of enhancing how we work and the experiences we deliver.
